 Click here to see this example >>>
Click here to see this example >>>The first thing you need to know is the correct term for a page is 'document'. The second thing is how to create a text file. If you're using Windows or some other graphical desktop simply right click on the desktop and make a new text file and then rename it to index.html I won't bore you with the technicalities of why but the front page (home page) of a website is nearly always called index.html
You don't need any expensive or complicated web authoring software to make your web page, simply open your built-in text editor (Notepad on Windows) and open the file. The first thing we need to add is some standard tags that go in pretty much all web documents. Notice how start and end tags can be embedded inside one another to create a hierarchical structure. This adds greater meaning to the document. Put these tags into your open index.html file and save the file. Remember tosave the file every time you add to it.
<html> <head> </head> <body> </body> </html>
This is the most basic structure of most web pages. The <html></html> tags surround the entire content and the page has a head <head></head> section and a body section <body></body>. Again the tags are quite logically named and these tell the web browser what language the document is written in (there are other languages but one step at a time, they are covered elsewhere on the Internet) and that it has a head and body section. The head section contains information about the document, the body section contains the information the document displays to the wider audience.
You will probably have noticed that up to this point this paper has discussed XHTML yet so far we're created a document called index.html and put <html></html> tags in it. You may be confused by this but there is a simple analogy to help explain this. HTML is the language of the Internet much as English is a language. English has many dialects or vairiations in its usage, one of the most obvious examples of these is American English which contains both alternative spellings and alternative meanings of some English words. XHTML is a dialect of HTML, in our analogy XHTML would be something akin to "The Queen's English": a gramatically correct, pure version of the language.
Browser software will make its own best guess at how to display a web document. This isn't a perfect solution as this varies greatly from one browser to another, in the same way people from different locations would read a slightly different intperpretation of a written dialect of English. The solution is to gain complete control of how the browser shows the document to the end user by putting specific information into the code to instruct the browser how to lay the document out on the screen to a standardised layout, (in this case W3C's XHTML 1.1. standard). You have to add three things to your file to achieve this, rather like giving the browser a translation phrase book.
Add the DTD or Document Type Definition at the very top of the file. This is a standard string of text and must be the very first thing in the document. The standard DTD for XHTML 1.1 is:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
The document is written in XHTML which is a dialect of HTML. Add the location of the 'XHTML 1.1 phrase book' to the starting <html> tag (no point telling it after the event is there?) by adding and xmlns attribute which provides the browser with a place to find the correct definitions of the tags used in the document. In addition specify that these tags are in English using the lang attribute to the value en for English .
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
The final thing to do is tell the browser exactly which character set to use to display the text in the document and what type of content will be in the document body. English uses the Western alphabet, we will use the Internationally defined iso-8859-1 character set. The type of characters you are reading now. This is information about the document itself and is known as meta information. Pretty straight forwardly, it is named the <meta></meta>. As stated above, information about the document is stored head section. Add the meta tag and its attributes between the start and end head tags along with the first two pieces and your document should look contain this code.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> </head> <body> </body> </html>
Note how the <meta /> tag has been written without an end tag but with a space and a forward slash character before the > The meta tag has attributes but no content (nothing to hold between start and end tags, commonly described as an 'empty tag') the use of a single tag with an additional trailing slash <meta /> is a shorthand expression for <meta></meta>.
This is not a multilingual tutorial, the object of the excercise is to get the reader creating XHTML 1.1 standard compliant web pages in English and with the western character set. The tags as shown in the sample code are the correct ones for the type of web page you are trying to create, there are many different configurations and these are discussed in detail at http://www.w3c.org/ . Just take this for granted for the time being. The subject of document types is a very large and confusing can of worms and this is not the time to open it.
The document title is another piece of information about the document and is also as a result included in the head section of the source code. Source code is the term given to the tags (or markup). The document title appears at the very top of your browser window, above the menus in the window bar. The title is also used by search engines such as Google and Yahoo as the text in any link to your document.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head> <title>Dave Howe</title> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> </head> <body> </body> </html>
Add in the content of your web page between the <body></body> tags of the document so that it is displayed on the screen in the browser window.
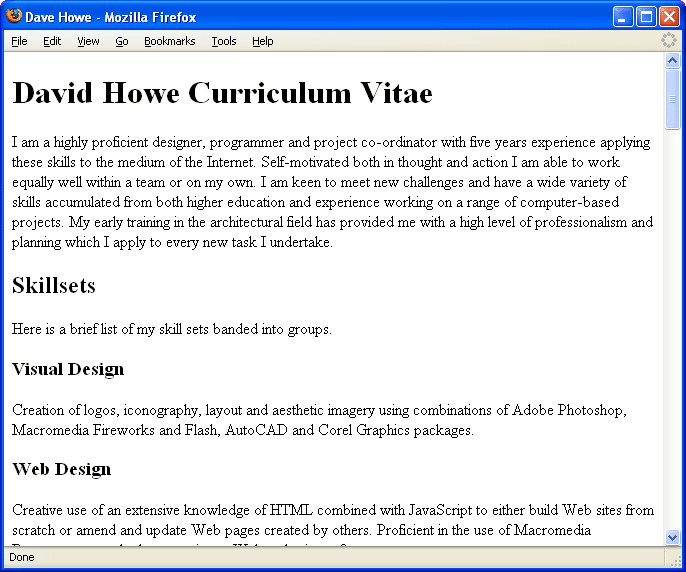
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head> <title>Dave Howe</title> <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> </head> <body> <h1>David Howe Curriculum Vitae</h1> <h2>Skill Sets</h2> <p>Here is a list of my skillsets</p> <h3>Visual Design</h3> <p>Creation of logos, iconography, layout and aesthetic imagery using Adobe Photoshop, Macromedia Fireworks and Flash, AutoCAD and Corel Graphics packages.</p> <h3>Web Design</h3> <p>Creative use of an extensive knowledge of HTML combined with JavaScript to either build Web sites from scratch or amend and update Web pages created by others. Proficient in the use of Macromedia Dreamweaver and other proprietary Webauthoring software.</p> </body> </html>
Click here to see this example >>>
I added in the rest of my CV so the page has a larger amount of content in readiness for the steps that follow. The structure uses multiple subheading tags from <h1></h1> to <h5></h5>.
Click the screenshot and hold the mouse down and the image should enlarge so you can see the result clearer (doesn't work in Internet Explorer 6 or earlier).
Click the link to see the example document ina browser window. View the source code for the example document by placing your mouse pointer over the page and click the right mouse button and choose 'View Source' or 'View Page Source' from the mouse menu. This option is also usually available in the 'View' menu at the top of the browser window. You can view the source code of most web documents. Back in 1993 I started learning about HTML and building web pages by looking at the document source code and trying to work out which tags did which things. This approach is still as valid for a beginner today as it was back then but beware bad code. There are a lot of examples of bad coding on the Internet that may confuse a beginner. If you view the source of a site and the code looks messy and complicated move on to another page as that one is probably exhibiting all the wrongs this paper is trying to put right.
Click here to learn how to add a navigation list menu to your web document >>>
